Windows11でスタートアップのexeソフトを登録する

Windows起動時に自動で立ち上がるソフトの登録方法。
Windows + Rキーを押してshell:startupを入力。
そうするとスタートアップフォルダが開くのでそこに自動で立ち上げたいソフトのショートカットをコピーする。
フォルダのパスはこれC:\Users\ユーザー名\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
Windows起動時に自動で立ち上がるソフトの登録方法。
Windows + Rキーを押してshell:startupを入力。
そうするとスタートアップフォルダが開くのでそこに自動で立ち上げたいソフトのショートカットをコピーする。
フォルダのパスはこれC:\Users\ユーザー名\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
このサイトが正しくgzipやbrotli圧縮になっているか調べるためにGoogle chromeブラウザの開発者ツールで確認してみると、なぜかリクエストヘッダーにAccept-Encodingが含まれず、圧縮したファイルをリクエストできない現象が出た。
curlコマンドで確かめるとbrotli圧縮には対応しているし、EdgeやFirefoxではちゃんとリクエストが送れている。
Chromeの仕様かと思いポータブル版のChromeを入れて確かめてみるとリクエストヘッダーにAccept-Encodingがあるので、メインで使ってるChromeが完全におま環状態だった。
結局この症状を検索しても直し方がわからなかったのでChromeを再インストールすることにした。
このときWindowsだとプログラム一覧からアンインストールしてもユーザーデータが残ってしまうので、C:\Users\ユーザー名\AppData\Local\Google\Chromeのフォルダを削除してから再インストールする。
そうすることで正しくリクエストにaccept-encodingを含めることができ、レスポンスヘッダーにcontent-encoding:brでbrotli圧縮されたファイルをリクエストすることができた。
エックスサーバーにGithubのアカウントをssh接続してプライベートリポジトリを簡単にクローン出来るようにしたい。
まずエックスサーバーにssh接続して
ssh-keygen -f .ssh/githubこのコードでサーバー内でsshの秘密鍵と公開鍵を生成。
Enter passphrase (empty for no passphrase): みたいなメッセージでパスフレーズを聞かれるので何も入力せずEnter。
鍵が生成出来たらconfigファイルを作成して.sshディレクトリに置く。configファイルの中身はこんな感じ↓
Host github.com
User Githubのユーザー名
IdentityFile ~/.ssh/github
configファイルが作れたら.sshディレクトリの中にあるgithub.pubの中身をコピーする。
そしたら自分のGithubのアカウントページを開き、右上のアカウントのアイコンをクリックしてsettingをクリック。左のメニューからSSH and GPG keysを選択してNew SSH keyボタンを押して先ほどコピーしたgithub.pubの中身をペーストする。
キーを登録したらをコマンドラインから
ssh -T git@github.comを打ち、The authenticity of host 'github.com、、、みたいなメッセージが出たらyesを打つ。Hi ユーザー名! You've successfully authenticated, but GitHub does not provide shell access.というメッセージが出たら成功。
適当なディレクトリでgit clone git@github.com:ユーザー名/リポジトリ名.gitを打ち、クローン出来ているか確認する。
そのままだとコマンドが長いので.bash_profileあたりにエイリアスを登録しておくと便利。
alias gclone='function _gclone() { git clone git@github.com:ユーザー名/$1.git $2; }; _gclone'上記のエイリアスだとgclone リポジトリ名 クローンするディレクトリ名(任意)でクローンすることができる。
現在の株価を取得をしたかったのでPythonでスクレイピングすることにした。
主に米国株の情報が欲しかったのでリアルタイムで更新されているGoogleファイナンスにすることにした。
そのサイトがスクレイピングが許可されているかどうかはrobots.txtを見ればわかる。
https://www.google.com/robots.txt
投稿時点でAllow: /financeと記載されているので多分大丈夫だと思う。
必要なパッケージはBeautifulSoup4とrequestsなので環境になければインストールする。
pip install BeautifulSoup4 requests完成コードはこんな感じ。
from bs4 import BeautifulSoup
import requests
def data_get(symbol, lang="ja"):
url = f"https://www.google.com/finance/quote/{symbol}?hl={lang}"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
name = soup.find(class_="zzDege").text # 会社名
prices = soup.find_all(class_="YMlKec fxKbKc") # 株価
p_lis = []
for i in prices:
p_lis.append(i.get_text())
try:
after = p_lis[1]
except IndexError:
after = None
others = soup.find_all(class_="P6K39c") #その他データ
o_lis = []
for i in others:
o_lis.append(i.get_text())
return {
"会社名": name,
"価格": p_lis[0],
"時間外取引": after,
"前日終値": o_lis[0],
"日次変動幅": o_lis[1],
"年間変動幅": o_lis[2],
"時価総額": o_lis[3],
"平均取引高": o_lis[4],
"株価収益率": o_lis[5],
"配当利回り": o_lis[6],
"優先市場": o_lis[7],
}
print(data_get("NVDA:NASDAQ"))
# 実行結果
{
'会社名': 'NVIDIA',
'価格': '$135.91',
'時間外取引': '$135.61',
'前日終値': '$140.11',
'日次変動幅': '$134.22 - $139.92',
'年間変動幅': '$53.49 - $153.13',
'時価総額': '3.33兆 USD',
'平均取引高': '2.09億',
'株価収益率': '53.55',
'配当利回り': '0.03%',
'優先市場': 'NASDAQ'
}Googleファイナンスは"銘柄コード(シンボル):取引市場"で株情報を管理しているので、そこのURLを変数にして使いやすくした。言語についてはヘッダーやURLになにもつけずにリクエストすると英語で返ってくるので?hl={lang}で言語を指定する。日本語ならja。
URLからhtmlを取得してBeautifulSoupを使ってクラス名でその要素を取得する。クラス名が変わってしまうと使えなくなるので、もし変更があればその都度変更しなければならない。
class_="YMlKec fxKbKc"で株価を取得していて時間外取引の値も取得できるけど、日本株は時間外取引の記載がないのでIndexErrorで処理している。
前日比のデータも取りたかったけどその部分はJavascriptで表示させてるっぽいのでレンダリングさせなきゃならない。seleniumを使えばいけるだろうけど、そこまでするのだったら素直にGoogleスプレッドシート使う方が簡単だと思う。
あと日本株は20分ぐらい遅延があるそうなのでPythonならyfinance使った方がいい。米国株ならリアルタイムで取得できるので便利。
昨日のpipに引き続き、今日はよく使うcondaコマンドのメモ。
# condaのバージョン確認
conda -V
# condaの詳細情報確認
conda info
# condaの仮想環境を作る
conda create -n 環境名 python=バージョン
# condaの環境の一覧表示
conda env list
# condaの環境をアクティブに
conda activate 環境名
# condaの環境から抜ける
conda deactivate
# condaの仮想環境の削除
conda env remove -n 環境名
# condaでインストールされているパッケージの表示
conda list
# condaでパッケージのインストール
conda install パッケージ名=バージョン
# condaで利用可能なパッケージの表示
conda search パッケージ名
# condaでパッケージのアップデート
conda update パッケージ名
# 全てのパッケージのアップデートを確認
conda update --all --dry-run
# 全てのパッケージのアップデート
conda update --all
# condaでパッケージのアンインストール
conda remove パッケージ名
# conda自体をアップデート
conda update conda
# 指定された環境にあるパッケージの書き出し
conda env export -n 環境名 > ファイル名.yml
# ファイルからパッケージの読み込み
conda env create --file ファイル名.yml
# 不要なキャッシュ等の削除
conda clean --allconda clean --allは危ないみたいな記事見かけたけど自分の場合は大丈夫だった。でも環境によって違うのかも。よーわからん。
いつも忘れるため、ここにメモ。
# パッケージのインストール
pip install パッケージ名==バージョン
# パッケージのアンインストール
pip uninstall パッケージ名
# パッケージ一覧表示
pip list
# アップデートがあるパッケージを全て表示
pip list -o
or
pip list --outdated
# 最新(アップデートのない)のパッケージの表示
pip list -u
# 特定のパッケージの詳細情報の表示
pip show パッケージ名
# 特定のパッケージをアップデート
pip install -U パッケージ名
or
pip install --upgrade パッケージ名
# パッケージを全てアップデート
pip list --outdated --format=freeze > outdated.txt
pip install -r outdated.txt --upgrade
# 現在の環境にあるパッケージをテキストファイルに書きだす
pip freeze > ファイル名.txt
# テキストファイルにあるパッケージを全てインストールする
pip install -r ファイル名.txt
# テキストファイルにあるパッケージを全て削除する
pip uninstall -r packages.txt -ycondaは一括アップデートがあるのにpipはないのは不便だなあ。
リストの特定の値の両隣の値を取得したいときがあったのでメモ。
def get_neighbor(target, lis):
try:
target_index = lis.index(target)
before_value = lis[target_index-1] if target_index > 0 else False
after_value = lis[target_index+1]
except IndexError:
after_value = False
except ValueError:
before_value = False
after_value = False
return before_value, after_value引数に特定の値とそのリストを渡す。
特定の値のインデックスが0の場合、リストの一番最後の値を指定してしまうのでif文でFalseを入れる。
特定の値がリストの最後の場合、IndexErrorでFalseを入れる。
多分もっといい書き方があると思うけど自分しか使わないしこれでいい。
iPhoneのSafariブラウザでJavascriptが動作しないときがあったので解決法をメモ。iOSのバージョンは18.1.1。
設定からアプリのSafariをクリック。トップの画面で下にスワイプすると検索バーが表示されるので、そこにSafariと入力すると直接いけるので便利。
Safariページの一番下までスクロールして詳細をクリック。
設定>アプリ>Safari>詳細
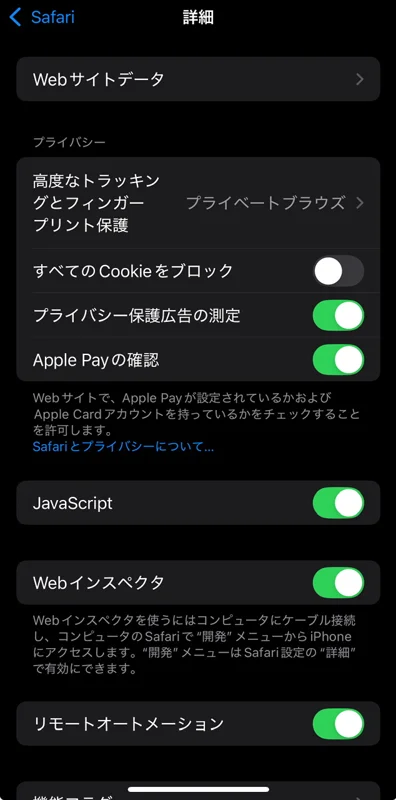
そうしたら上記の画像の画面になるのでJavaScriptを1度OFFにして再度ONにしてSafariで目的のページをリロードするとJavascriptが正常に動作した。
このサイトでは記事のタグ分けに同じsvgファイルを複数表示させているのだけれど読み込みが遅い。
ということでなぜ読み込みが遅いか調べてみると、どうもobjectタグで同じsvgファイルを読み込むとぞれぞれ別のファイルとして扱われてレンダリングに時間がかかるらしい。
実験として同じsvgファイルをimgタグとobjectタグで100個ずつ読み込んだhtmlをそれぞれ用意してみた。
この2つのページをChromeで開くと圧倒的にobjectタグで読み込んだ方が遅い。
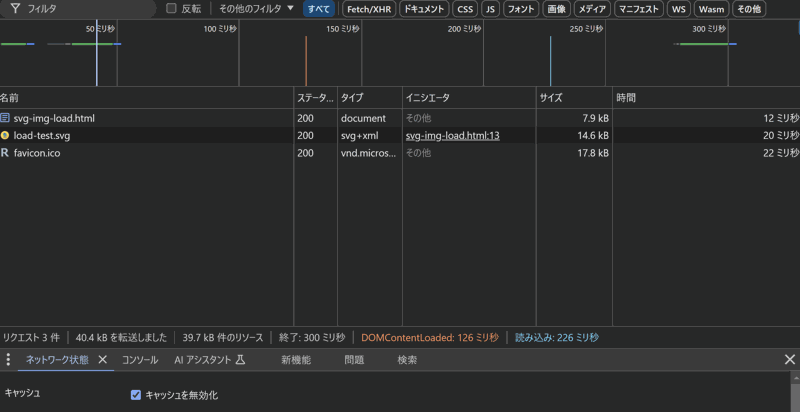
結果としてはimgタグで読み込んだものがこれ
objectタグで読み込んだ方がこれ
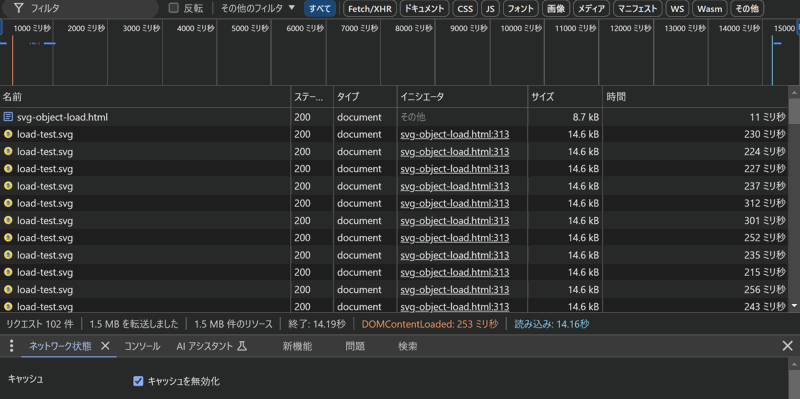
imgタグで読み込むと同じファイルは1度しか読み込まれていないけど、objectのほうは1つずつ読み込まれて描画に時間がかかり、リクエスト量も転送量も読み込み時間も増えている。
ネットの他の記事ではsvgファイルを読み込むときはobjectタグで読み込んだ方が便利という記事が多いけど、役割にあった読み込み方法をお勧めする。
結論:同じsvgファイルを複数使い、アニメーションさせたり特殊な使い方をしないのであればimgタグで読み込んだ方が速い。
ただしこれはChrome特有のものみたいなので、MicrosoftのEdgeやiOSのSafariブラウザではobjectのほうが遅いけどChromeよりは断然早い。なので将来的にChromeもobjectタグによるsvgファイルの読み込みが今より速くなるかもしれない。
このサイトを作ってGoogleサーチコンソールの設定をしようとしたらエックスサーバーのサーバーパネルのデザインが変わっていたので備忘録。
サーバーパネルから左のドメインからDNSレコード設定を選択する。
右上のドメイン選択から追加したいドメインを選んで青文字のDNSレコード設定の追加を選択すると下記の画像の画面になる。
サーバーパネル>ドメイン>DNSレコード設定>DNSレコード設定を追加
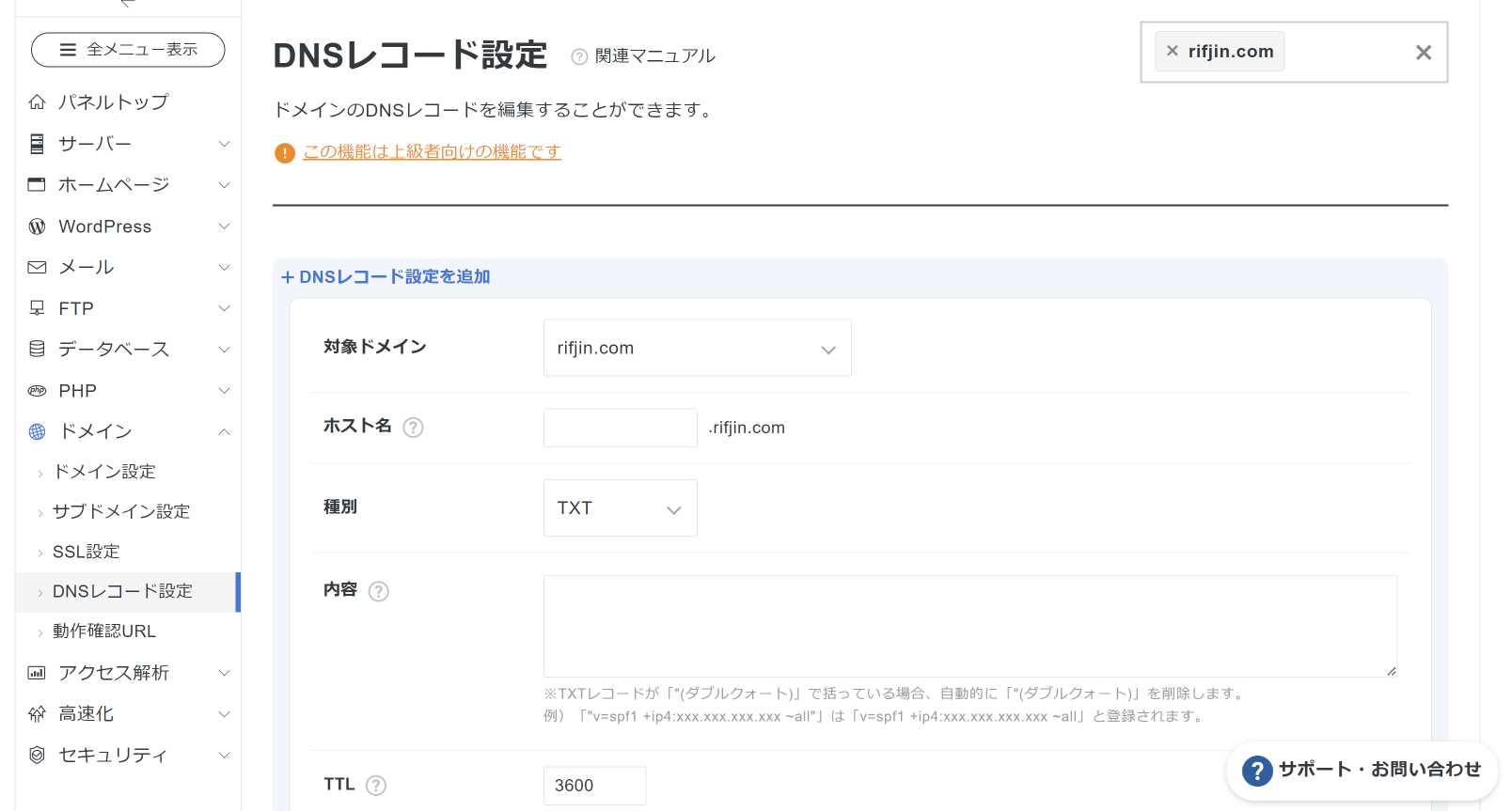
対象ドメインは追加したいドメイン、ホスト名は空白のまま、種別はTXT、内容はサーチコンソールでコピーしたTXTレコードを張り付け、TTLはそのまま、優先度はTXTでは設定できないのでこれもそのままで右下にある追加するを押す。
そしてサーチコンソールに戻って確認を押すとプロパティが追加できる。
その際、確認が早すぎると失敗するので少し時間を置く。私の場合5分ほどで反映された。
PythonのFlaskのrender_templateで引数に変数と変数名を渡すとJinja2テンプレートで使用することができる。
しかし、特定のデータをすべてのrender_templateで使いたいときいちいち書くのも面倒なので、一括で渡せる設定方法がFlaskには用意されている。
hoge = "hoge"
common_data = {"hoge": hoge}
@app.context_processor
def inject_data():
return common_data@app.context_processorの中の関数のReturnに辞書型の変数を渡してやるとキーの値を使用してJinjaテンプレートで使うことができる。
PythonのFlaskを触っているとrender_templateの関数でRuntimeError: Working outside of application context.というエラーが出た。プログラミング初心者なので始めは何のことやらわからかったが、調べるとFlaskの関数はFlaskのアプリケーションコンテキストの中でしか実行できないらしい。
つまり、
@main.route('/test')
def test():
index_html = render_template("index.html")
return index_html上記のコードは実行できるが
index_html = render_template("index.html")
@main.route('/test')
def test():
return index_htmlこのコードはrender_templateがコンテキストの外にあるのでエラーとなる。
どうしてもルーティングや他のコンテキスト内で実行したいときは
with app.app_context():
# ここに書くこのwithの中に書くとエラーが出ずに実行できる。
VscodeでPythonの1行のコメントアウトはeditor.tokenColorCustomizationsのcommentsで変更できる。
けどなぜかクォーテーション3つで囲む複数行のコメントアウトの色が適用されなかったのでここにメモする。
"editor.tokenColorCustomizations": {
"textMateRules":[{
"scope": "string.quoted.docstring.multi.python",
"settings":{ "foreground": "#b0c4de" }
}],
},setting.jsonに上記のコードを書いてforegroundの部分に好きな色を設定する。
ScopeはコマンドパレットにInspect Editor Tokens and Scopesと打ってエディタートークンとスコープの検査を選択して確認できる。


